Pentaho es una suite de inteligencia de negocio completa que incluye:
- Pentaho Data Integration: Una solución visual para desarrollar ETLs e integración de datos entre aplicaciones.
- Pentaho Report Designer: Una herramienta gráfica de generación de informes.
- Pentaho Server: Es el servidor que integra todas las soluciones, como cubos OLAP, los informes desarrollados por Report Designer, informes ad-hoc y cuadros de mando.
- Pentaho metadata editor: Es una herramienta que permite construir metadatos que pueden ser accesibles desde los informes adhoc u otros componentes de Pentaho.
- Pentaho schema workbench: Es el editor de cubos OLAP
Además de estas soluciones, Pentaho, desde su marketplace, también puede integrar herramientas de terceros como Weka, Saiku, dashboards de Ivy.
Pentaho sigue un modelo de núcleo abierto, disponiendo de dos versiones: la versión de la comunidad (totalmente software libre) y la versión Enterprise, que se adquiere mediante un modelo de suscripción.
Pentaho Data Integration
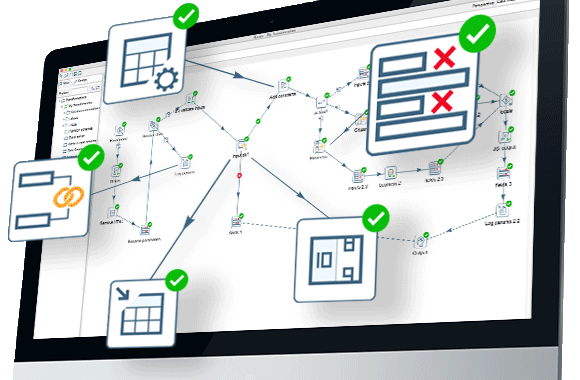
Elija una plataforma de un extremo a otro para todos los desafíos de integración de datos. Esta intuitiva interfaz gráfica de arrastrar y soltar simplifica la creación de procesamientos de datos. Para la transformación de datos, puede usar fácilmente el procesamiento push-down para escalar las funcionalidades de computación en entornos locales y de nube
Funciones del producto
- Interfaz de arrastrar y soltar para crear procesamiento de datos
- Archivos planos, RDBMS, big data, almacenes de objetos, API.
- Operacionalice los modelos R, Python, Scala y Weka.
- Amplia conectividad a prácticamente cualquier fuente de datos.
- Salesforce.com y Google Analytics.
- Scikit-learn, Spark MLlib, TensorFlow y Keras.
- Combine datos donde sea que estén, en las instalaciones o en la nube.
- Soporte de carga masiva para almacenes de datos populares en la nube.
- Escalabilidad, contenedorización y seguridad.
Fácil de usar
Visualización en linea y paso a paso de datos en el procesamiento y la orquestación del modelo de aprendizaje automático
Diseño ligero
La arquitectura en contenedores permita la ingesta, combinación, preparación y visualización de datos
Procesamiento Big Data
Permite cambiar sin problemas entre el motor nativo y Apache Spark para procesar cualquier fuente de datos a escala
Algunas de las implementaciones que hemos llevado a cabo